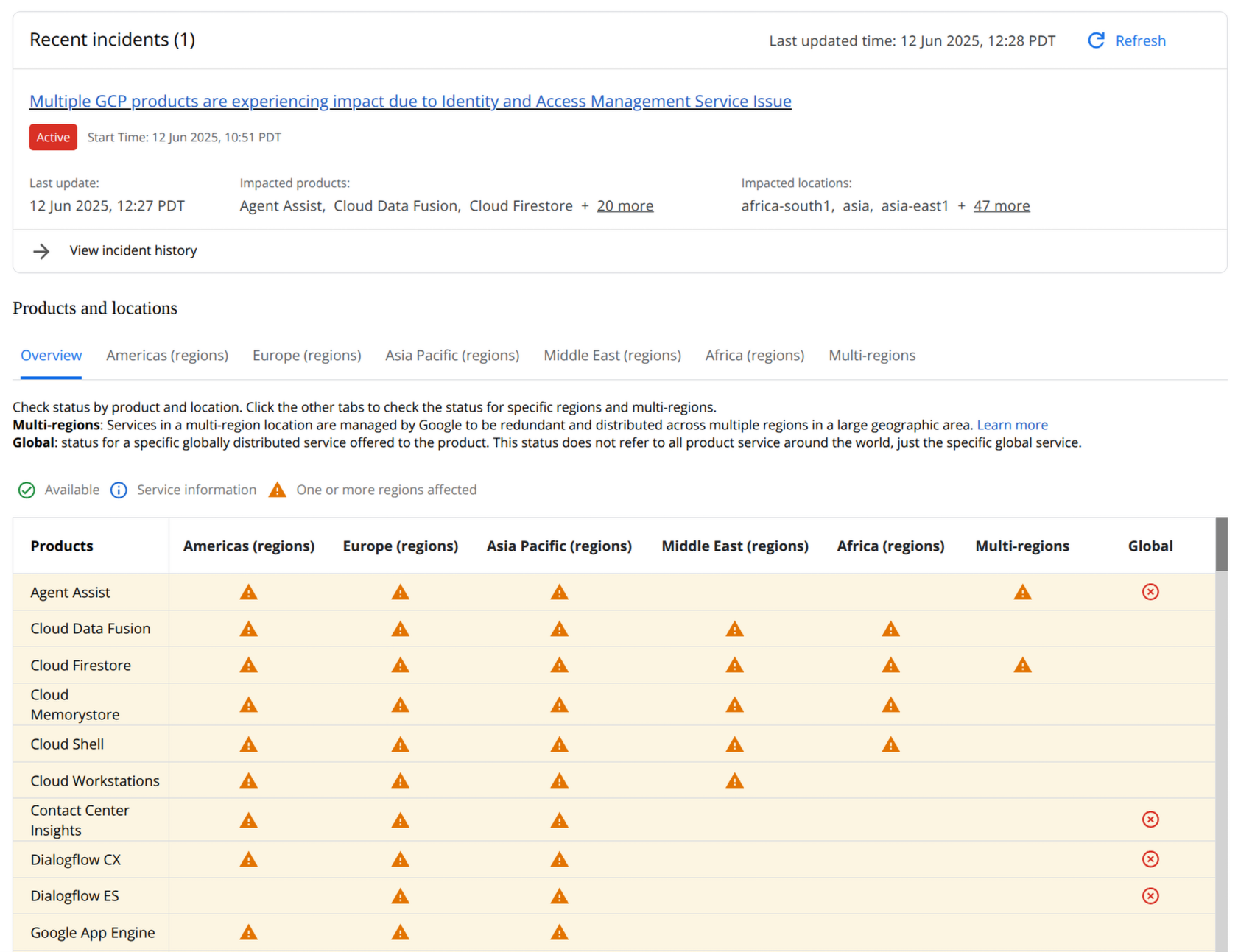
Today is a tough day to run cloud software on the internet - especially if you run on Google’s Cloud (GCP). Many sites that leverage GCP are being impacted by an outage.

According to Google’s status page it’s due to an issue with the Identity and Access Management service.
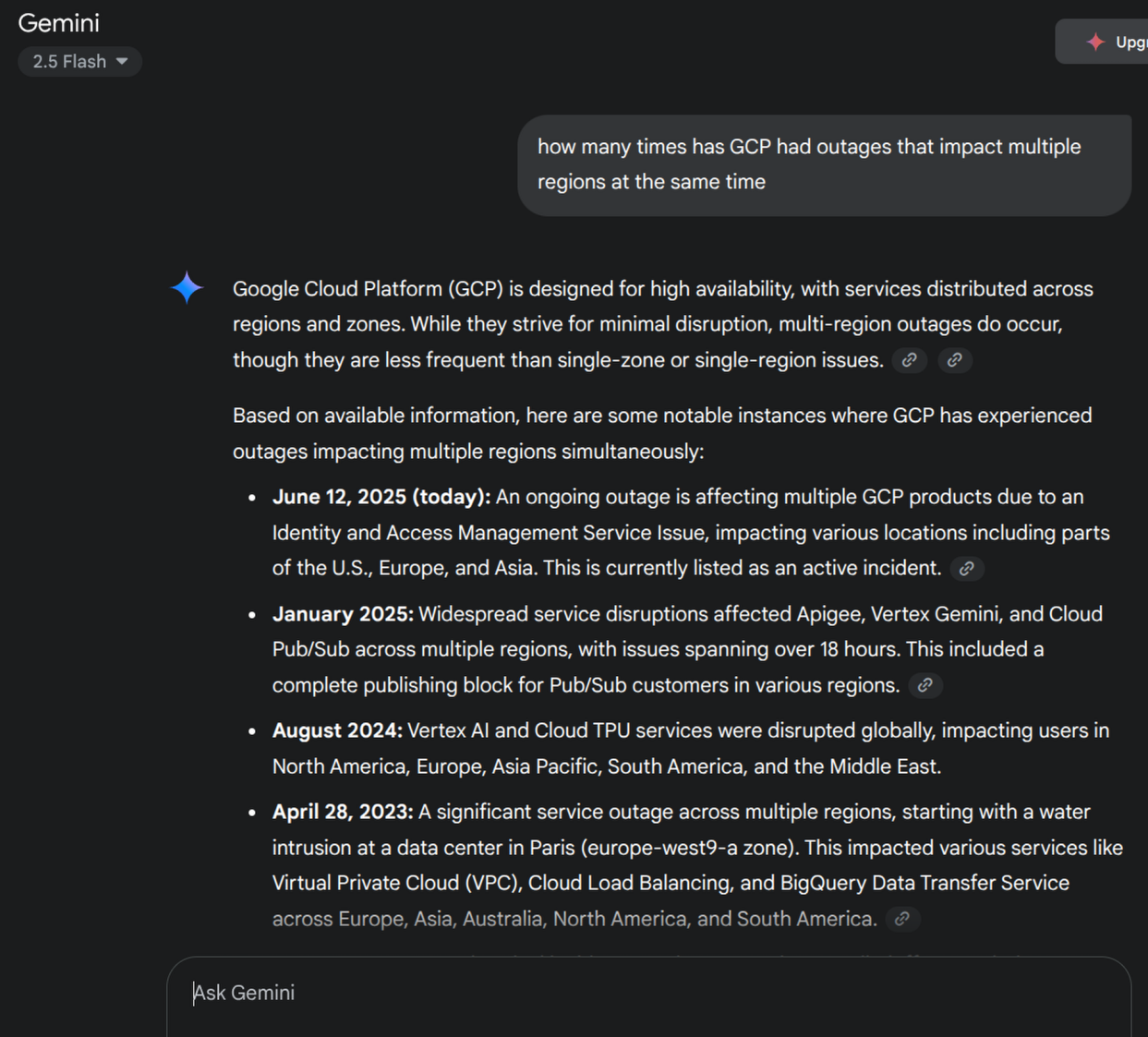
It certainly seems like GCP has more multi-region outages than AWS. At least Gemini provides a pretty good summary of previous ones.
If I had to speculate, it feels like much of this comes back to Google having a bias towards global services while AWS has one towards regional ones.
OK, so what can we learn?
After running cloud services for a number of years, I learned to never throw stones at other service providers when they have outages. Everyone who runs services will likely experience a service availability issue at some point in there career. Instead I’ve found these are great opportunities to learn.
- What happened and how did it occur?
- Could this impact my service, and if so could I do something now to prevent this from occuring to me?
- Is there an architectural pattern that is at the root of the issue and needs to be addressed?
Global vs. regional architectures
While AWS has had their share of outages you do rarely see them impacting many regions at once (besides a handful of global services like Cloudfront). This is because they work very hard to keep every part of a region isolated from the other regions.
Nobody wants to have global outages that impact a number of regions at the same time. This is why we work so hard to spread our service out across regions, data centers, etc.
Evolution of a service provider
Most cloud startups begin with a simple app in a single region - say app.myservice.com and host it in a
single cloud region. They build their customer base and assuming it goes well they likely have customers
from around the world using their service (because you made it easily localized/globalized right?).
Eventually, many of these international customers will be so happy using the service they start worrying
about data sovereignty and ask to keep their data in their
region to comply with local laws. Or maybe the performance is better for their growning user-base
because the speed of light still takes 130ms to get around the globe.
Guidance - TLDR
While it is tempting to think you can solve all of the challenging technical problems of managing a multi-region distributed service I’d suggest that it will be a more complicated and harder problem than you first believe and will rarely be worth it for most service providers.
Instead I would suggest creating many isolated instances of the service in each region - app.myservice.eu, app.myservice.jp, etc.
This should be the same software artifacts and deployment process in all regions with different config for each.
And typically this would be staggered across staging, and production regions so you catch deployment related issues
in one before deploying to higher risk ones.
You can see many service providers already are following this pattern.